Before Quiz
Learning
$p(\theta\vert\mathcal D)$
- $p(\mathcal D\vert \theta)p(\theta)$ closed-form solution
- $L(\theta)$
- $b=\nabla_\theta L(\theta)$
- $H=\nabla^2_\theta L(\theta)$
$\theta^+\leftarrow \theta - H^{-1}b$
$p(\theta\vert\mathcal D)= \mathcal N(\theta_\text{MAP},H_\text{MAP}^{-1})$
Prediction
$t_{N+1} = y(x_{N+1},\theta)+v$, $v\sim \mathcal N(0,\beta^{-1})$
$p(t_{N+1}\vert x_{N+1},\mathcal D) =\mathcal N(y(x_{N+1},\theta_\text{MAP})+\bar q_\text{MAP}^\text{T}H^{-1}_\text{MAP}\bar q_\text{MAP})$
$y(x_{N+1},\theta)=\delta?(\Phi^\text T(x_{N+1})\theta)$
$p(t_{N+1}\vert x_{N+1},\mathcal D) =p(t_{N+1}\vert x_{N+1},\mathcal \theta_\text{MAP}) =(y(x_{N+1},\theta_\text{MAP}))^{t_{N+1}}(1-y(x_{N+1},\theta_\text{MAP}))^{1-t_{N+1}}$
Evaluation
Question 1 Neural Networks without Prior
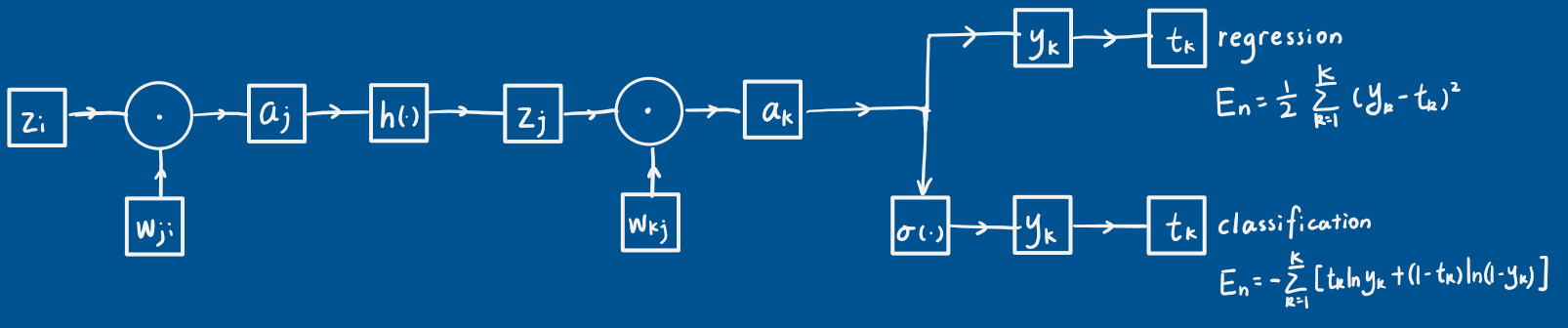
Question 1.1
What are the gradients of $\frac{\partial y_k}{\partial w_{kj}}$, $\frac{\partial y_k}{\partial w_{ji}}$ for regression and classification, respectively?
Solution 1.1
Regression
Classification
Question 1.2
What are the gradients of $\frac{\partial E_n}{\partial w_{kj}}$, $\frac{\partial E_n}{\partial w_{ji}}$ for regression and classification, respectively?
Solution 1.2
Regression
Classification
Question 1.3
What’s the gradients of $\frac{\partial y_k}{\partial z_i}$ for regression and classification, respectively?
Solution 1.3
Regression
Classification
Question 2 Neural Networks with Prior
If the prior of $w\sim \mathcal N(m_0,\Sigma_0^{-1})$ for both regression and classification, then
Question 2.1
What are the MAP solutions of $w,p(w\vert\mathcal D)$ for both cases?
Solution 2.1
By iterating $w^\text {new}=w^\text {old}-A^{-1}\nabla E(w)$, we obtain $w_\text{MAP}$.
Regression
Classification
where $\mathbf H$ is the Hessian matrix of the sum of error function.
Hence we have $p(w_\text{MAP}\vert \mathcal D) = \mathcal N(w\vert w_\text{MAP},A^{-1})$.
Question 2.2
What are the predictive distributions of a new data input $x_{N+1}$ and label $t_{N+1}$ for both cases?
Solution 2.2
Regression
Classification