Outline
- Introduction
- Preliminary
- Distributions
- Linear Models for Regression
- Linear Models for Classification
- Neural Networks
- Sparse Kernel Machines
- Mixture Models and EM Learning
- Sequential Data
- Markov Decision Process
Chapter 1 - Introduction
Concepts
- Machine Learning—minimization of some loss function for generalizing data sets with models.
- Datasets—annotated, indexed, organized
- Models—tree, distance, probabilistic, graph, bio-inspired
- Optimization—algorithms can minimize the loss
Linear Optimization Model
Find $X^\star$ to minimize the loss function:
Euclidean Distance Optimization
Point $x_0$, model $\mathbf b^\text Tx=d$.
We have:
Lagrange optimization:
Convex Optimization
Unconstrained optimization
Gradient descent
Gauss-Newton’s Method
Use a second-order approximation to function:
Choose $\Delta x$ to minimize above:
Descent direction:
Batch Gradient Descent
Minimize empirical loss, assuming it’s convex and unconstrained.
- Gradient descent on the empirical loss
- Gradient is the average of the gradient for all samples
- Very slow when $n$ is very large
Stochastic Gradient Descent
Compute gradient from just one or a few samples
Constrained optimization
- Lagrange methods
- Bayesian methods
Non-convex Optimization
- Heuristic algorithms
- Random search
Algorithms
- Bayes
- KNN
- K-means
- Decision Tree
- SVM
- Boosting
- Ensemble Learning
- Linear Statistical Learning
- Nonlinear Statistical Learning
- Deep Neural Networks
- Generative Adversarial Networks
- Bayesian Networks
- Reinforcement Learning
- Federated Learning
Chapter 2 - Preliminary
Curve Fitting and Regularization
Polynomial Curve Fitting
Sum-of-Squares Error Function
Root-Mean-Square (RMS) Error
where $\mathbf w^\star=\mathop{\text{argmin}}\limits_{\bf w}\ E(\bf w)$.
Regularization
Discourage the coefficients from reaching large values.
where $|{\bf w}|={\bf w}^T{\bf w}=w_0^2+w_1^2+\cdots+w_M^2$.
Note that often the coefficient $w_0$ is omitted from the regularizer because its inclusion causes the results to depend on the choice of origin for the target variable (Hastie et al., 2001), or it may be included but with its own regularization coefficient
Probabilities Theory
Basic Concepts
Marginal/Joint/Conditional Probability
Sum/Product Rule
Probability Densities
Bayes’ Theorem
Prior/Posterior Probability
Transformed Densities
Expectations
Variances and Covariances
Gaussian Distribution
The Gaussian Distribution
Gaussian Mean and Variance
Likelihood Function
For a data set of independent observations $\mathbf x = (x_1,\cdots,x_N)^\text T$ of a Gaussian Distribution, its likelihood function is
Log Likelihood Function:
By maximizing the log likelihood function, we have
corresponding to the sample mean and the sample variance.
Properties of $\mu_{ML}$ and $\sigma^2_{ML}$
The MLE will obtain the correct mean but will underestimate the true variance by a factor $\frac{N-1}{N}$ (bias).
Curve fitting re-visited
Given $x$, the corresponding value of $t$ has a Gaussian distribution with a mean equal to the value $y(x, \mathbf w)$.
where $\beta$ is the precision parameter corresponding to the inverse variance of the distribution: $\beta^{-1}=\sigma^2$.
Training data:
- Input values $\mathbf x=(x_1,\cdots,x_N)^\text T$
- Target values $\mathbf t=(t_1,\cdots,t_N)^\text T$
Log likelihood function:
- The last two terms do not depend on $\bf w$, omitted.
- Dividing a positive constant $\beta$ does not alter $\mathbf w_{ML}$, replace $\frac \beta 2$ with $\frac 1 2$.
So maximizing the likelihood function is equivalent to minimizing the sum-of-squares error function $\sum\limits_{n=1}^N\{y(x_n,\mathbf w)-t_n\}^2$.
After obtaining $\mathbf w_{ML}$, we can further maximize the likelihood function w.r.t. $\beta$:
Substitute $\mathbf w_{ML}$ and $\beta_{ML}$ back to get predictive distribution:
MAP: Maximum Posteriori
Review: the Multivariate Gaussian:
where $\alpha$ is the precision of the distribution(hyperparameter), and $M+1$ is the total number of elements in the vector $\bf w$ for an $M^\text{th}$ order polynomial.
Bayes’ Theorem: the posterior distribution for $\bf w$ is proportional to the product of the prior distribution and the likelihood function.
Take the logarithm of the rhs, we already know the likelihood function and prior distribution mentioned above, therefore maximizing posterior is to minimizing the following:
Maximizing the posterior distribution is equivalent to minimizing the regularized sum-of-squares error function, with regularization parameter $\lambda = \frac\alpha\beta$.
Bayesian Curve Fitting
Assume that the parameters $\alpha$ and $\beta$ are fixed and known in advance.
In Bayesian treatment, the predictive distribution can be written as:
$p(t\vert x,\mathbf x, \mathbf t)$ is the likelihood function with omitted dependence on $\alpha$ and $\beta$ .
$p(\mathbf w\vert\mathbf x,\mathbf t)$ is the posterior distribution which can be found by normalizing the rhs.
For problems such as curve-fitting, this posterior distribution is a Gaussian and can be evaluated analytically. Similarly, the integration can also be performed analytically.
The predictive distribution is given by a Gaussian of the form
where the mean and variance are given by
Here the matrix $\textbf S$ is given by
where $\textbf I$ is the unit matrix, the vector $\phi(x)$ with elements $\phi_i(x)=x^i$ for $i=0,\cdots,M$.
- The variance and the mean depend on $x$.
- $\beta^{-1}$ represents the uncertainty in the predicted value of $t$, expressed in the maximum likelihood predictive distribution through $\beta^{-1}_{ML}$.
- $\phi(x)^\text T\textbf S\phi(x)$ arises from the uncertainty in $\mathbf w$ and is a consequence of the Bayesian treatment.
Model Selection
S-fold Cross Validation

leave-one-out: $S=N$
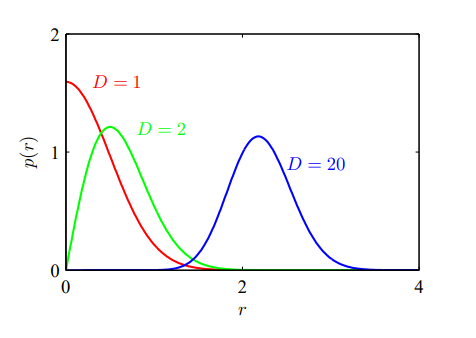
Curse of Dimensionality
For a polynomial of order $M$, the growth in the number of coefficients is $D^M$.
In spaces of high dimensionality, most of the volume of a sphere is concentrated in a thin shell near the surface, most of the probability mass of a Gaussian is located within a thin shell at a specific radius.
Decision Theory
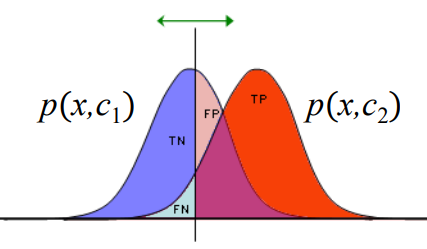
Confusion Matrix
| Truth/Decision | Positive | Negative |
|---|---|---|
| Positive | TP | FN |
| Negative | FP | TN |
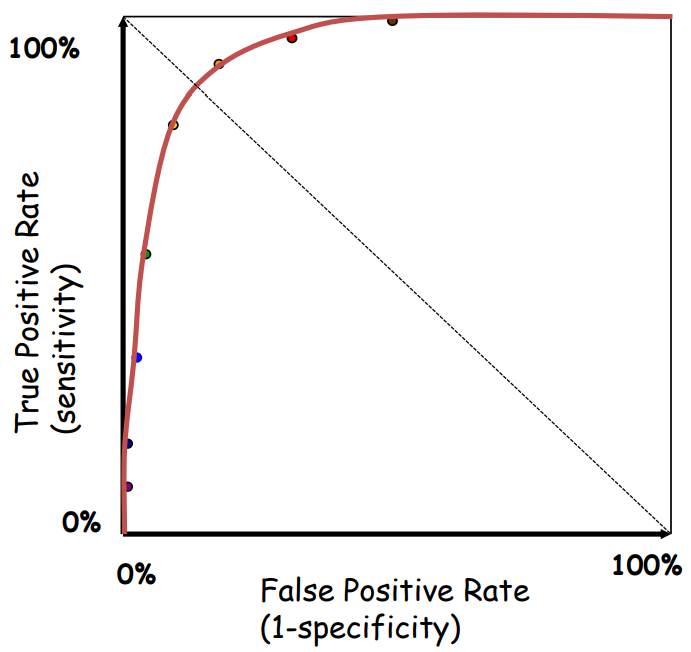
Receiver Operating Characteristic Curve
Minimizing the misclassification rate
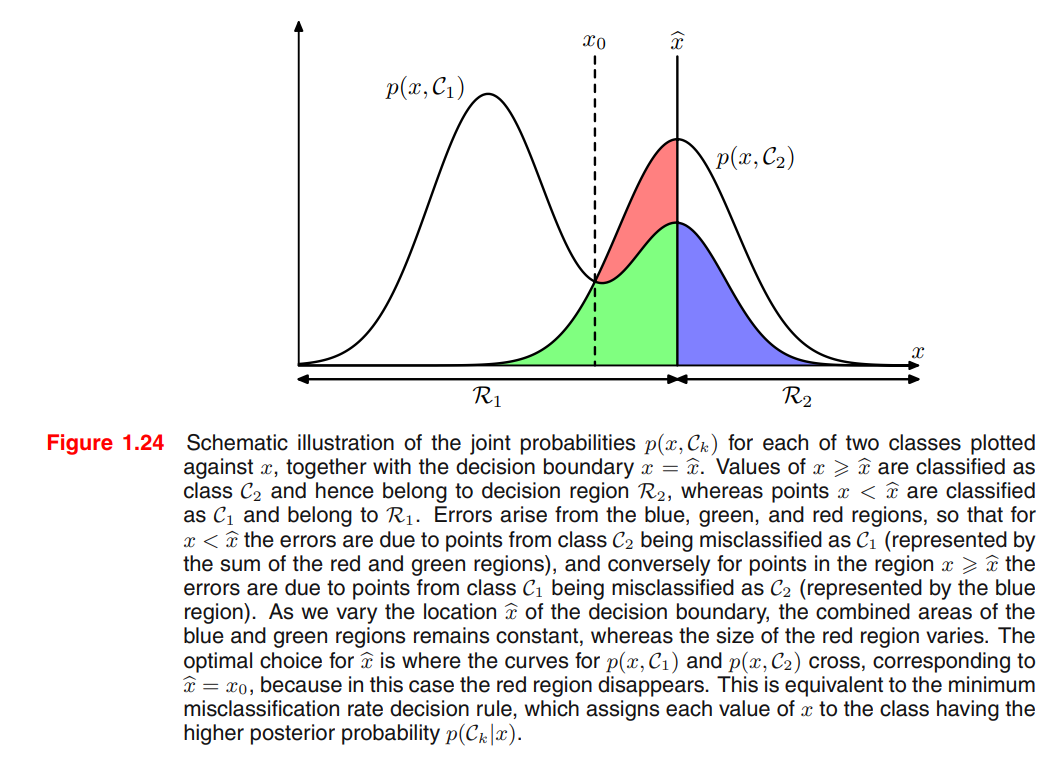
Minimizing the expected loss
Each $\mathbf x$ can be assigned independently to one of the decision regions $\mathcal R_j$.
Goal is to choose $\mathcal R_j$ to minimize $\mathbb E[L]$, we should minimize $\sum\limits_{k} L_{kj}p(\mathbf x,\mathcal C_k)$ for each $\mathbf x$.
Common factor $p(\mathbf x)$ can be eliminated from $p(\mathbf x,\mathcal C_k)=p(\mathcal C_k\vert\mathbf x)p(\mathbf x)$.
Thus the decision rule that minimizes the expected loss is the one that assigns each new $\mathbf x$ to the class $j$ for which the quantity $\sum\limits_{k} L_{kj}p(\mathcal C_k\vert\mathbf x)$ is a minimum.
Reject Option
Introducing a threshold $\theta$ and rejecting those inputs $x$ for which the largest of the posterior probabilities $p(\mathcal C_k\vert \mathbf x)$ is less than or equal to $\theta$.
- $\theta=1$: all examples are rejected.
- $\theta<\frac 1 K$: ($K$ classes) no examples are rejected.
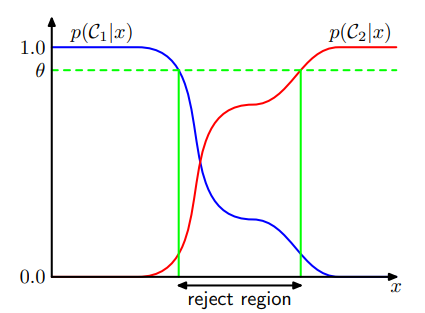
Inference and Decision
Generative model: Model the distribution of inputs as well as outputs. Because by sampling from them it is possible to generate synthetic data points in the input space.
Discriminative model: model the posterior probabilities directly.
Discriminant function: Learn a function that maps inputs x directly into decisions.
3 Ways to Solve Decision Problems
(a) By inference, determine $p(\mathbf x\vert \mathcal C_k)$ and $p(\mathcal C_k)$, then uses Bayes’ Theorem
Equivalently, we can model the joint distribution $p(\mathbf x, \mathcal C_k)$ directly and then normalize to obtain the posterior probabilities. (generative model)
(b) By inference, determine the posterior class probabilities $p(\mathcal C_k\vert\mathbf x)$ directly. (discriminative model)
- (c) Find a function $f(x)$, called a discriminant function, which maps each input $\mathbf x$ directly onto a class label. Probabilities play no role.
Pros/Cons of the three approaches(extract from PRML)
Let us consider the relative merits of these three alternatives. Approach (a) is the most demanding because it involves finding the joint distribution over both
However, if we only wish to make classification decisions, then it can be wasteful of computational resources, and excessively demanding of data, to find the joint distribution
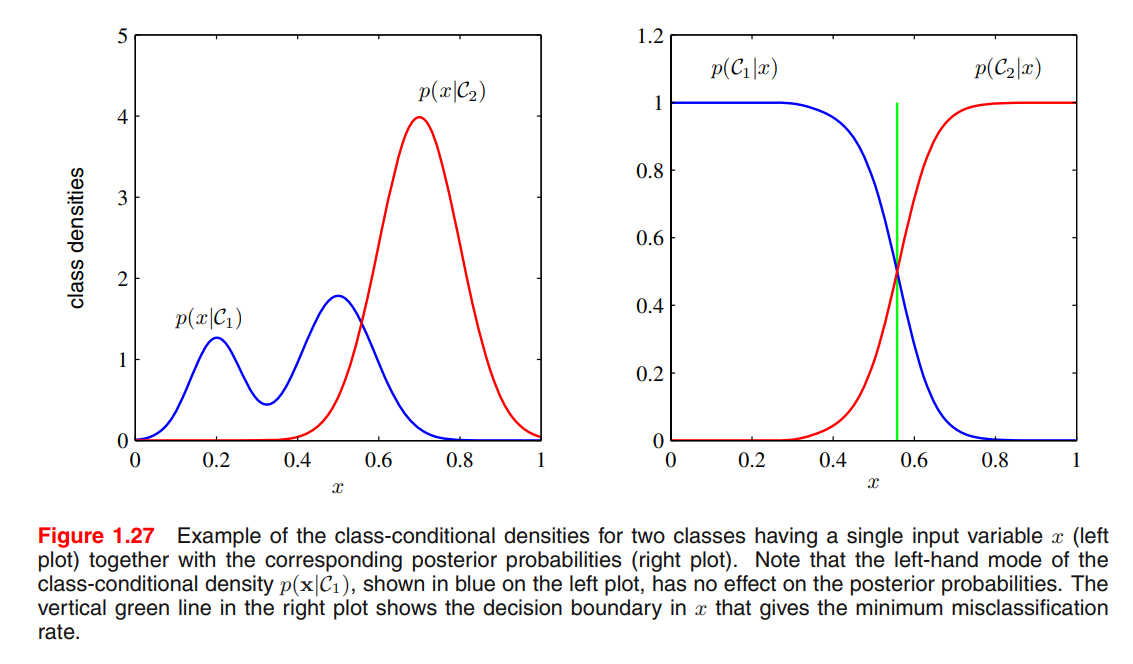
An even simpler approach is (c) in which we use the training data to find a discriminant function
With option (c), however, we no longer have access to the posterior probabilities
- Minimizing risk.
- Reject option.
- Compensating for class priors.
- Combining models.
Loss functions for regression
For each input $\bf x$, choose a specific estimation $y(\bf x)$ of the value $t$.
Take squared loss $L(t,y({\bf x}))=\{y({\bf x})-t\}^2$ for example
Method 1. Calculus of Variations
Using a calculus of variations to give $y({\bf x})$ so as to minimize $\mathbb E[L]$:
Solving for $y({\bf x})$, and using the sum and product rules of probability, we obtain the regression function:
which is the conditional average of $t$ conditioned on $\bf x$.
Method 2. Expanding the square term
Substitute into the loss function and perform the integral on $t$:
When $y({\bf x})=\mathbb E_t[t\vert \mathbf x]$, loss function $\mathbb E[L]$ is minimized.
The second term represents the intrinsic variability of the target data and can be regarded as noise, or minimum value of the loss function.
3 Ways to Solve Regression Problems (in order of decreasing complexity)
- (a) Inference to determine the joint density $p({\bf x},t)$, then normalize to find the conditional density $p(t\vert \mathbf x)$, finally marginalize to find the conditional mean by the regression function.
- (b) Inference to determine the conditional density $p(t\vert \mathbf x)$, then marginalize to find the conditional mean by the regression function.
- (c) Find a regression function $y(\mathbf x)$ directly from the training data.
The relative merits of these three approaches follow the same lines as for classification problems.
Minkowski loss
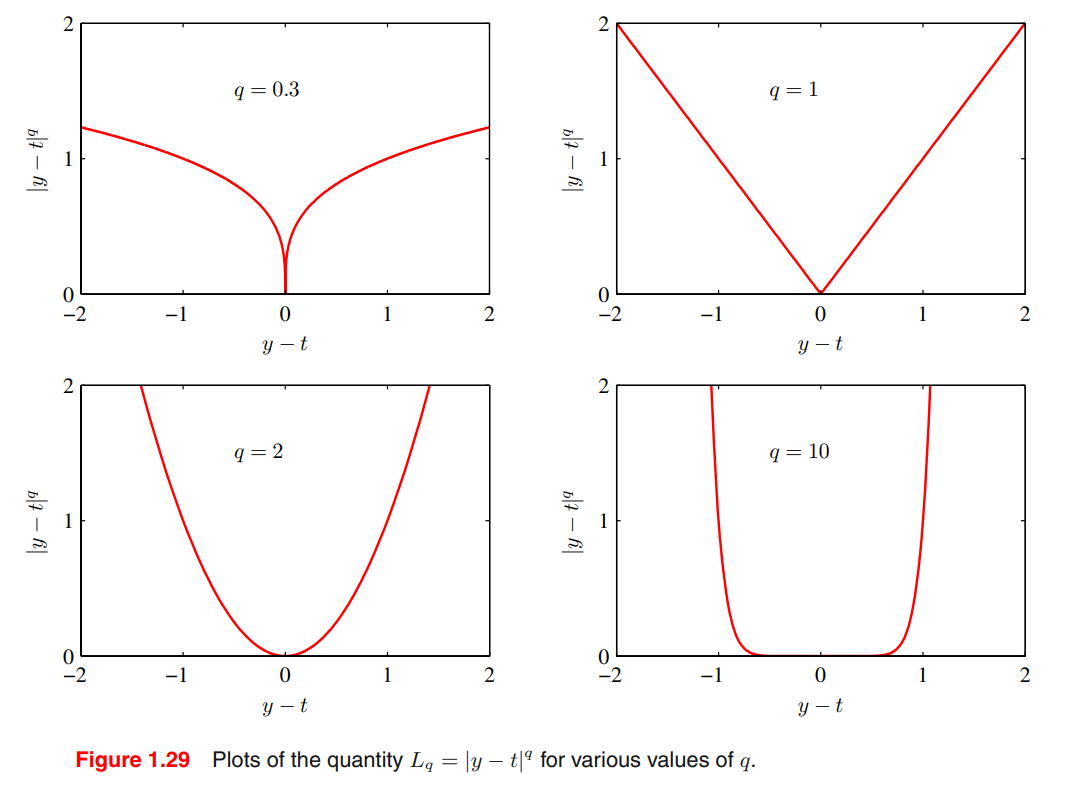
The minimum of $\mathbb E[L_q]$ is given by:
- $q\rightarrow 0$: conditional mode
- $q=1$: conditional median
- $q=2$: conditional mean
Information Theory
Entropy(statistical)
Discrete
Allocate $N$ identical objects in $M$ bins.
Entropy maximized when $\forall i,\ p_i=\frac 1 M$.
Continuous
Put bins of width $\Delta$ along the real line.
For fixed $\sigma^2$, when $p(x)=\mathcal N(x\vert\mu,\sigma^2)$, differential entropy is maximized
Entropy
Conditional Entropy
Relative Entropy (The Kullback-Leibler Divergence)
KL divergence describes a distance between model $p$ and model $q$.
- It is not a symmetrical quantity: $\text{KL}(p|q)\not\equiv \text{KL}(q|p)$.
- $\text {KL}(p|q)\ge 0$, with equality IFF $p(\mathbf x)=q(\mathbf x)$.
Approximate distribution $p(\mathbf x)$ using distribution $q(\mathbf x\vert\boldsymbolθ)$ governed by a set of adjustable parameters $\boldsymbol\theta$. One way to determine $\boldsymbol\theta$ is to minimize the KL divergence between the two distributions.
The 1st term is the negative log likelihood function for $\boldsymbol\theta$. The 2nd term is independent of $\boldsymbol\theta$. So minimizing this KL divergence is equivalent to maximizing the likelihood function.
Cross Entropy for Machine Learning
- Goal of ML: $p(\text{real data})\approx p(\text{model}\vert\theta)$
- We assume: $p(\text{training data})\approx p(\text{real data})$
- Operation of ML: $p(\text{training data})\approx p(\text{model}\vert\theta)$
Minimizing $\text{KL}(p(\text{training data})|p(\text{model}\vert\theta))$ is equivalent to minimizing $\text C(p(\text{training data})|p(\text{model}\vert\theta))$ as $\text H(p(\text{training data}))$ is fixed.
Example. Bernoulli model
where $t_n$ is the training data and $\rho$ is the model parameter.
Example. Gaussian model
where $t_n$ is the training data and $\mu$ is the model parameter.
Mutual Information
Mutual information describes the degree of dependence between $\mathbf x$ and $\mathbf y$
Information Gain
Given $N$ balls and a balance, one of these balls is lighter.
$x$: one ball is lighter
$y$: weighing once
$\text H[x]$: uncertain of balls
$\text H[x\vert y]$: uncertain of balls after weighing once
Sum the equation above with $t=0,1,\cdots,T$,
Chapter 3 - Distributions
Binary Distributions
Bernoulli Distribution
Given $\mathcal D=\{x_1,\cdots,x_N\}$, $m$ heads, $N-m$ tails.
Binomial Distribution
Beta Distribution
The Beta distribution provides the conjugate prior for the Bernoulli distribution.
Given $\mathcal D=\{x_1,\cdots,x_N\}$, $m$ heads, $N-m$ tails.
As the size of the dataset $N$ increases,
Multinomial Distributions
1-of-K coding scheme
1-of-K coding scheme: $\mathbf x=(0,0,1,0,0,0)^\text T,\ \sum\limits_{k=1}^Kx_k=1$.
where $\boldsymbol\mu=(\mu_1,\cdots,\mu_K)^\text T$, $\sum\limits_k\mu_k=1$.
Given $\mathcal D=\{\bf x_1,\cdots,x_N\}$, the likelihood
where $ m_k=\sum\limits_{n=1}^Nx_{nk}$ denotes the number of observations of $x_k = 1$.
Using Lagrange method, we obtain
Multinomial Distribution
Dirichlet Distribution
Conjugate prior for the multinomial distribution.
Given $\mathcal D=\{m_1,\cdots,m_K\}$, the likelihood
where $\mathbf m=(m_1,\cdots,m_K)^\text T$.
We can interpret the parameters $\alpha_k$ of the Dirichlet prior as an effective number of observations of $x_k = 1$.
Gaussian Distributions
The Gaussian Distribution
The Multivariate Gaussian
Central Limit Theorem
The distribution of the sum of $N$ i.i.d. random variables becomes increasingly Gaussian as $N$ grows.
Moments of the Multivariate Gaussian
Properties of Gaussians
- Linear transformation
Product of Gaussian r.v.
For multivariate Gaussians, use $\Sigma$ to replace $\sigma^2$.
Bayes’ Theorem for Gaussian Variables(Slides)
Given $y=Ax+v$, $p(x)=\mathcal N(x\vert\mu,\Sigma)$, $p(v)=\mathcal N(v\vert,0,Q)$.
Hence we have
Therefore
where
Conditional Gaussian distributions
If two sets of variables are jointly Gaussian, then the conditional distribution of one set conditioned on the other is again Gaussian.
Given a $D$-dimensional vector $\mathbf x$ with Gaussian distribution $\mathcal N(\mathbf x\vert\boldsymbol\mu,\boldsymbol\Sigma)$, partitioned into two disjoint subsets $\mathbf x_a$ and $\mathbf x_b$.
For conditional distribution $p(\mathbf x_a\vert\mathbf x_b)$,
And marginal distribution $p(\mathbf x_a)=\mathcal N(\mathbf x_a\vert\boldsymbol\mu_a,\boldsymbol\Sigma_{aa})$.
Bayes’ Theorem for Gaussian Variables(Textbook)
Given
Obtain
where
Maximum Likelihood for the Gaussian
Sufficient statistics: $\sum\limits_{n=1}^N\mathbf x_n$ and $\sum\limits_{n=1}^N\mathbf x_n\mathbf x_n^\text T$
Solve the maximum likelihood
Under the true distribution
Hence define
Sequential estimation
Bayesian Inference for the Gaussian
Student’s t-distribution
Periodic variables
Mixtures of Gaussians
$\pi_k$: mixing coefficients
$\sum\limits_{k=1}^K\pi_k=1,0\le\pi_k\le 1$
$N(\mathbf x\vert\boldsymbol\mu_k,\boldsymbol\Sigma_k)$: component
Log likelihood of mixtures
The maximum likelihood solution for the parameters no longer has a closed-form analytical solution.
Alternatives: iterative numerical optimization, expectation maximization.
Exponential Families
The exponential family of distributions over $\mathbf x$, given parameters $\boldsymbol \eta$
- $\bf x$: scalar or vector, discrete or continuous.
- $\boldsymbol\eta$: natural parameters
- $g(\boldsymbol\eta)$: normalization coefficient satisfying ↓
The Bernoulli Distribution:
So
The Multinomial Distribution:
Let $\mu_M=1-\sum\limits_{k=1}^{M-1}\mu_k$,
The Gaussian Distribution:
where
Maximum likelihood and sufficient statistics
Likelihood function
Condition of maximum likelihood estimator $\boldsymbol\eta_\text{ML}$
The solution for the ML estimator only depends on $\sum\limits_{n=1}^N\mathbf u(\mathbf x_n)$, which is called the sufficient statistic of the distribution.
For example,
Bernoulli distribution $\mathbf u(x) = x$, so we only keep the sum of the data points; Gaussian distribution $\mathbf u(x) = \left(\begin{matrix}x\\x^2\end{matrix}\right)$, we need to keep both the sum of data points and the sum of the square.
Conjugate Priors
Seek a prior that is conjugate to the likelihood function: the posterior distribution has the same functional form as the prior.
For any member of the exponential family, there exists a conjugate prior
where
- $f(\chi,\nu)$ is a normalization coefficient
- $g(\boldsymbol\eta)$ is the normalization coefficient of the exponential family.
Recall that
Multiply the prior and the likelihood, the posterior is
which is in the same functional form as the prior.
- $\nu$: effective number of pseudo-observations in the prior
- $\chi$: value of the sufficient statistic for the pseudo-observations
Non-informative Priors
Used when little is known about the prior distribution.
Have as little influence on the posterior distribution as possible.
Cons of choose constant as the prior
- If the domain of the parameter $\lambda$ is unbounded, the integral over $\lambda$ diverges, hence the prior cannot be normalized and is improper.
- By changing the variable(e.g., $\lambda=\eta^2$), the density over the new variable may not be constant.
Example: $\text{Gam}(\lambda\vert a_0,b_0)$ where $a_0=b_0=0$.
Non-parametric Methods
Limitation of parametric methods:
The chosen density might be a poor model of the distribution that generates the data. Multimodal data can never be captured by a unimodal Gaussian.
Histogram Methods
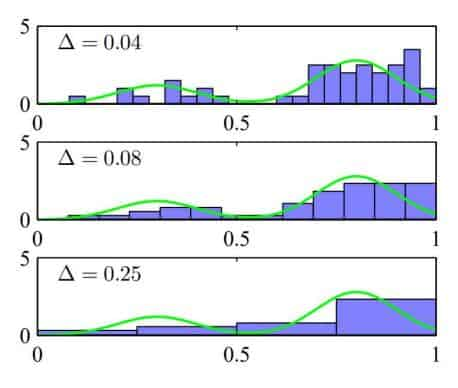
where $\Delta$ acts as a smoothing parameter.
Cons: Curse of Dimensionality
K-Nearest-Neighbors
Chapter 4 - Linear Models for Regression
Chapter 5 - Linear Models for Classification
Three Approaches to Classification
- Use discriminant functions directly
- Infer the posterior probabilities with generative models
- Directly construct posterior conditional class probabilities
Discriminant Functions
Discriminant Functions for $N$ classes
- use $N$ two-way discriminant functions
- use $\frac{N(N-1)}{2}$ two-way discriminant functions
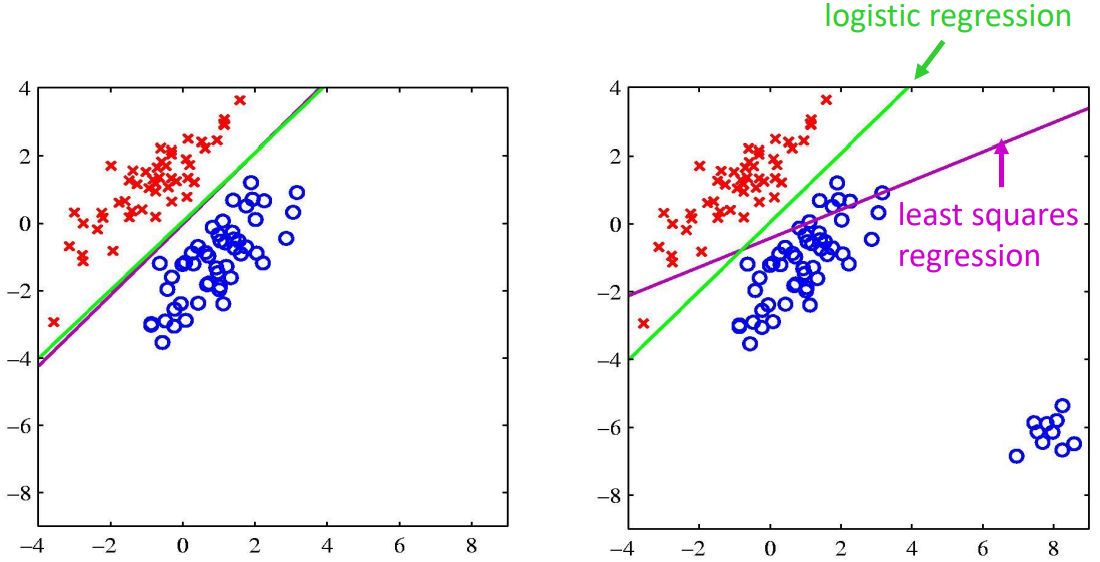
Least Square Classification
- Reduce classification to least squares regression.
- Treat each class as a separate problem, pick the max.
Least square regression is sensitive to outliers, use logistic regression to solve this problem:
Fisher’s Linear Discriminants(LDA)
See the course material for Lab06: LDA
Perceptron
Training
Criterion:
where $t_n\in\{1,-1\}$ is the label.
where $\eta$ is the learning rate.
indicating the convergence of perceptron training.
Simplified Training
- guaranteed to find a set of weights that gets the right answer on the whole training set if any such a set exists.
- no need to choose a learning rate.
Probabilistic Generative Models
where $z$ is called the logit
K-Case Classification
Generative: ML Gaussian Mixtures
Likelihood $p\left(\boldsymbol{t}, \boldsymbol{X} \vert \pi, \mu_{1}, \mu_{2}, \Sigma\right)=\prod_{n=1}^{N}\left[\pi N\left(x_{n} \vert \mu_{1}, \Sigma\right)\right]^{t_{n}}\left[(1-\pi) N\left(x_{n} \vert \mu_{2}, \Sigma\right)\right]^{1-t_{n}}$
Generative: MAP Gaussian Mixtures
Probabilistic Discriminative Models
Bayesian Information Criterion
Chapter 6 - Neural Networks

Chapter 7 - Sparse Kernel Machines
Support Vector Machines
Model: $\quad y(\mathbf x) = \mathbf w^\text T \phi(\mathbf x) + b$
Distance of a point to the decision surface
Rescaling $\mathbf w$ and $b$, the point closest to the surface(active constraint) satisfies:
Then the classification problem becomes:
Hard Margin Classifier
The classification problem:
where
Soft Margin Classifier
Introduce slack variables $\xi_n\ge 0, n=1,\dots,N$ (sometimes $\xi_n<0$ is allowed)
The classification problem:
where $C>0$ is the trade-off between minimizing training errors and controlling model complexity.
SVMs and Logistic Regression
Multiclass SVMs
- One vs. Rest: $K$ separate SVMs
- Can lead to inconsistent results
- Imbalanced training sets
- One vs. One: $\frac{K(K-1)}{2}$ SVMs
- dead zone
SVMs for Regression
过的很快,只用了一分半
※Relevance Vector Machines
Given an input vector $\mathbf x$, the conditional distribution for a real-valued target variable $t$:
where $\beta=\sigma^{-2}$ is the noise precision.
The mean is given by a linear model, which can be written in an SVM-like form:
where $k(\mathbf x,\mathbf x_n)=\phi(\mathbf x)^\text T \phi(\mathbf x_n)$ is the kernel, and $b$ is 616.a bias parameter.
Chapter 8 - Mixture Models and EM Learning
Chapter 9 - Sequential Data
Conditional data: independent of the previous states
Sequential data: dependent of the previous states
Markov models
first-order:
second-order:
Hidden Markov Models
For each observation $\mathbf x_n$, introduce latent variable $\mathbf z_n$, such that $\mathbf z_{n+1}\perp!!!!\perp \mathbf z_{n-1} \vert \mathbf z_n$
Use 1-of-K encoding, the latent variable is K-dimensional binary vector. The transition probability matrix $A_{j,k}\equiv p(z_{n,k}=1\mid z_{n-1,j}=1)$. This matrix satisfies $\sum\limits_{k} A_{jk}=1$ therefore has $K(K-1)$ independent parameters.
Chapter 10 - Markov Decision Process
Markov Decision Process
Given states $x$, actions $u$, transition probabilities $p(x’\mid u,x)$, reward function $r(x,u)$.
Expected cumulative reward:
- $T=1$: greedy
- $T>1$: finite horizon
- $T=\infty$: infinite horizon
Goal: optimal policy
T-Step Policy and Value Function
Value Iteration and Policy Iteration

